Ga naar de inhoud
Samen naar succes
Gericht op groei, gestuurd op data
Hecht team met topsportmentaliteit
Diensten
Diensten
Strategie
SEA
SEO
Social advertising
Conversie optimalisatie
Content
E-mailmarketing
Trainingen
Strategie
E-commerce
Leadgeneratie
International Growth
SEA
Google Ads
Microsoft Ads
Youtube Ads
Google Shopping
Marketplaces
SEO
Content
Linkbuilding
Techniek
AI-vindbaarheid
Social advertising
Facebook
Instagram
Pinterest
LinkedIn
TikTok
Short form content
Conversie optimalisatie
Conversie optimalisatie
Content
Content
Short form content
E-mailmarketing
E-mailmarketing
Trainingen
SEO-training
SEA-training
Social advertising training
Copywriting training
GA4-training
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Strategie
SEA
SEO
Social advertising
Conversie optimalisatie
Content
E-mailmarketing
Trainingen
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Strategie
Strategie
E-commerce
Leadgeneratie
International Growth
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
SEA
SEA
Google Ads
Microsoft Ads
Youtube Ads
Google Shopping
Marketplaces
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
SEO
SEO
Content
Linkbuilding
Techniek
AI-vindbaarheid
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Social advertising
Social advertising
Facebook
Instagram
Pinterest
LinkedIn
TikTok
Short form content
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Conversie optimalisatie
Conversie optimalisatie
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Content
Content
Short form content
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
E-mailmarketing
E-mailmarketing
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Trainingen
SEO-training
SEA-training
Social advertising training
Copywriting training
GA4-training
Even sparren?
Onze specialisten staan je graag te woord!
Ja, ik wil sparren
Ja, ik wil sparren
Cases
Over ons
Over ons
Het team
Onze werkwijze
Prijzenkast
Partners
Blog
Vacatures
4
Contact
Blog
Vacatures
4
Contact
Blijf op de hoogte van de laatste ontwikkelingen
Online marketing blog
Alles
Content
CRO
CRO|Events
E-commerce
E-mailmarketing
Events|SEO
NeoSEM
SEA
SEO
Social
Manon
Emerce E-commerce Live 2026: onze belangrijkste inzichten op een rij
Fieke
Goed nieuws: TikTok Shop Nederland lanceert op 15 juni!
Julia
Seedance 2.0: Wat is de laatste status van deze revolutionaire AI-videotool?
Madelaine
Wordt jouw merk geciteerd door AI?
Julia
Wat betekent AI adverteren voor SEA en performance marketing?
Julia
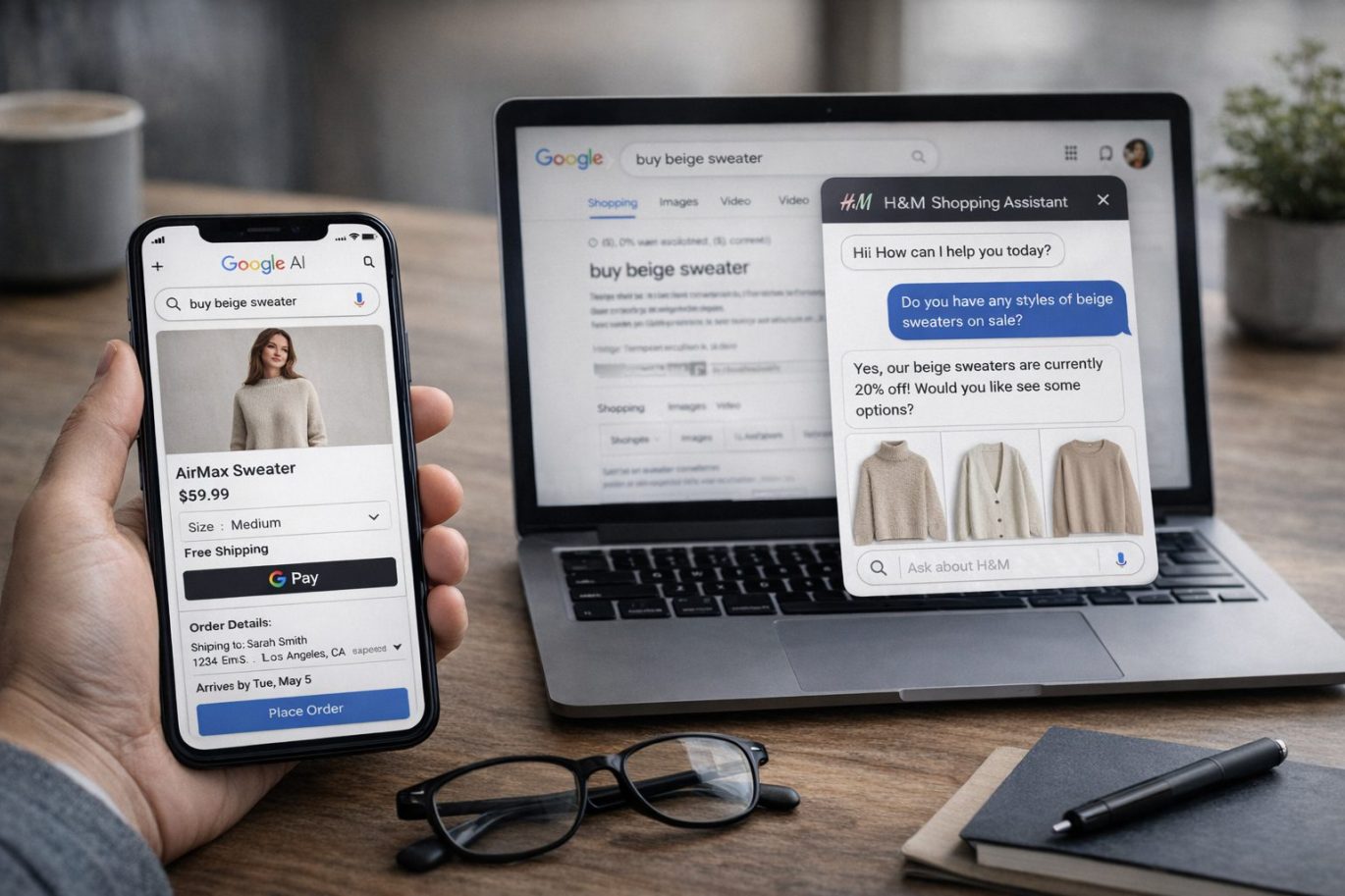
Google introduceert AI Mode Checkout en Business Agent, wat betekent dit voor e-commerce?
Julia
De hoogtepunten van 2025
sven
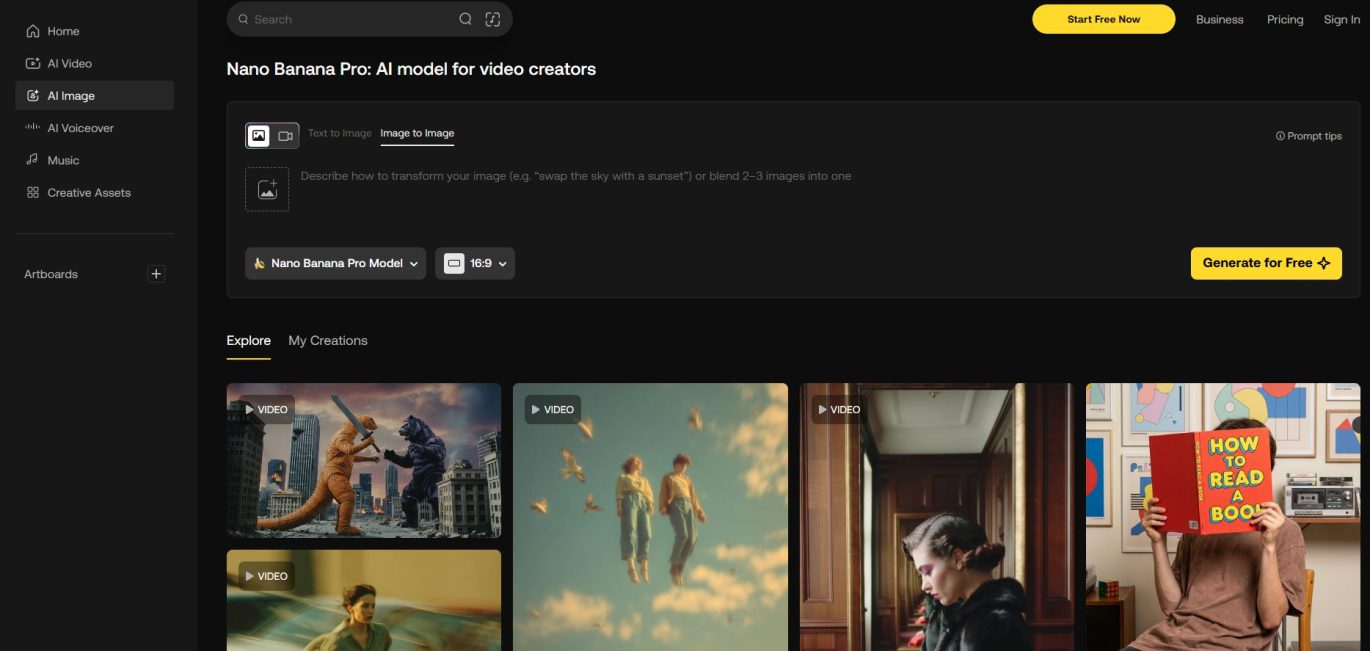
Google Nano Banana Pro: een nieuwe standaard voor visuele content?
Ruben B
Conversion Hotel 2025: drie dagen CRO-inspiratie op Texel
Jeffrin Don
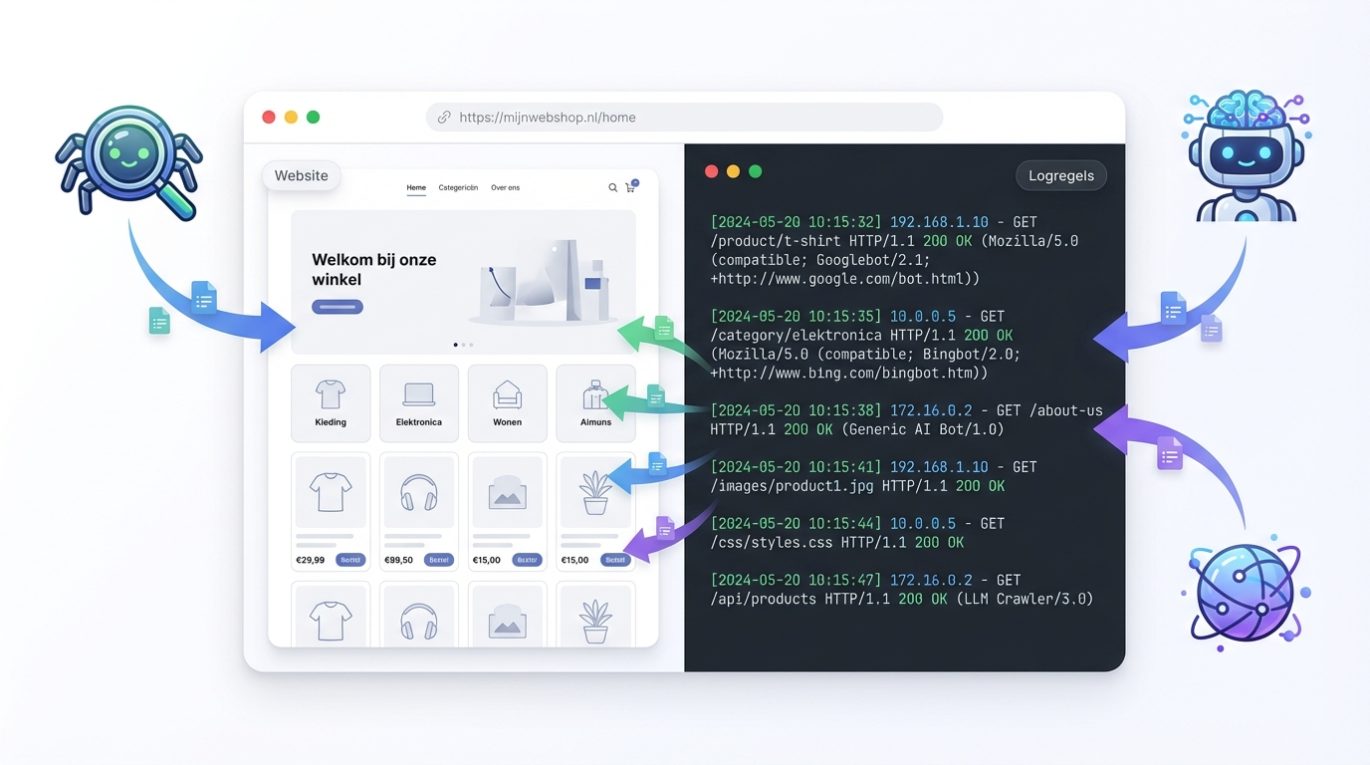
Meer grip op SEO met logfiles: zie wat Google écht doet op je site
Julia
Vijf jaar op rij in de FONK150, dit jaar beloond met een 9,7
Julia
De nieuwste social media trends in 2026
1
2
3
…
10
Volgende pagina